Tiny Search Engine
Project Summary
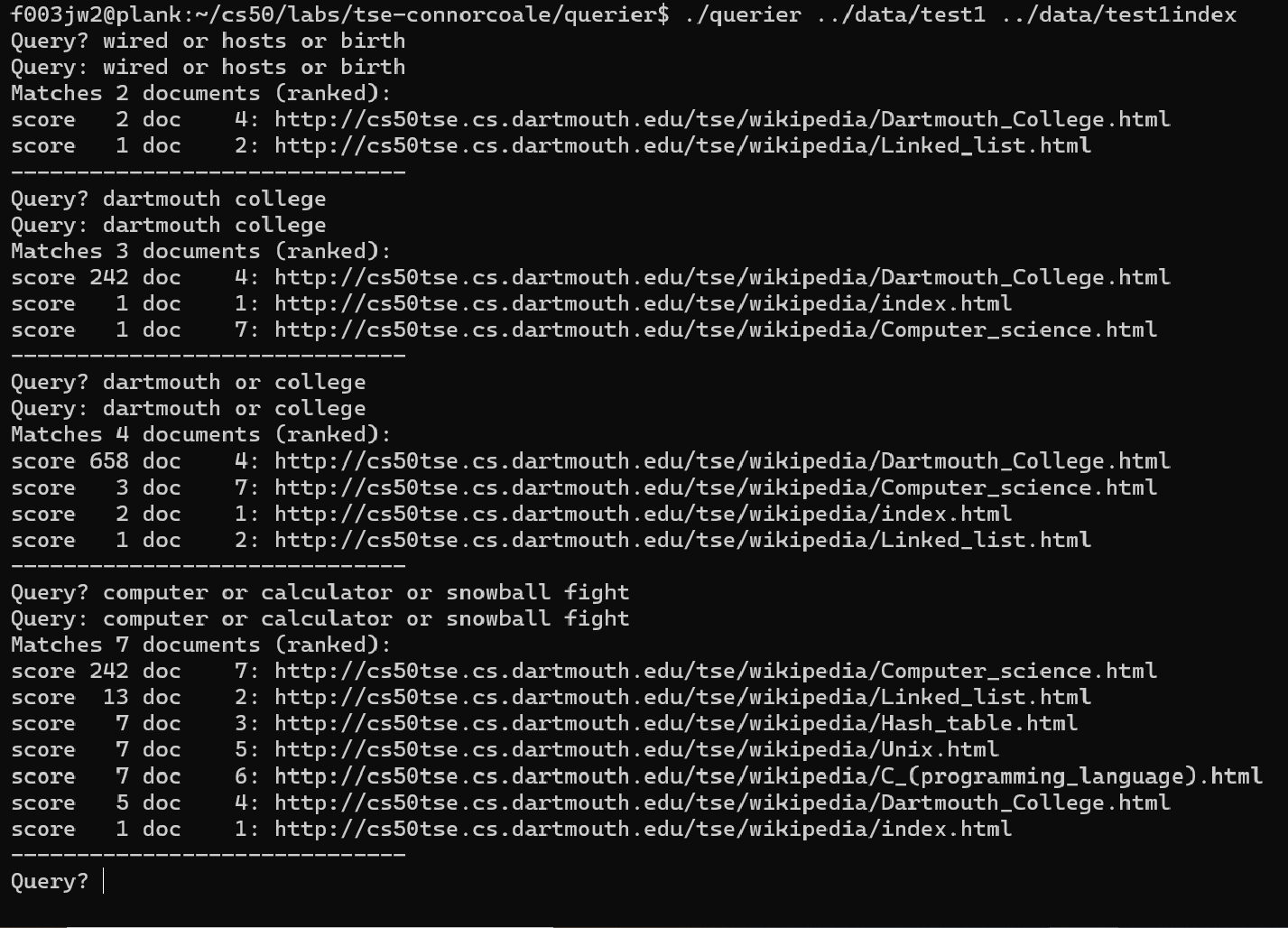
For this project, we were recreating crawling, indexing, and querying
as present in most modern search engines. The three modules, crawler,
indexer, and querier work collectively to scrape word frequency
data from a starting webpage down to a defined depth. The data is stored
and then may be queried with responsive searches which allow for useful
operators like AND and OR. It ranks the pages according to the relevance
to the search.
The search engine is written in C. The crawler scrapes html and stores unique
and unseen pages as files in the chosen file directory. It includes a unique ID number
as the file name, and the file contents include the URL, the depth, and the page
contents. The indexer
The puzzle solution and generation was written in C. To extend the
project beyond the basic scope, one of my team members also wrote a front and
backend for a web-based GUI, shown to the left, which was written in
Node and React.